還記得小李和他的餐廳帝國嗎?在上一個故事中,我們看到小李如何從一家小麵店發展成全球連鎖企業,也見證了監控系統從簡單的人工記錄演進到複雜的 EKS 微服務監控。
現在,故事要進入實戰階段了。小張(那位 Google 出身的 SRE 專家)決定手把手教小李的技術團隊,如何在 EKS 上安裝和配置 CloudWatch 可觀測性套件。
「理論講得再多,不如實際動手做一遍,」小張對小李說,「今天我們就來實際部署監控系統,讓你親眼看看這些神奇的工具是怎麼運作的。」
「在開始之前,我需要準備什麼嗎?」小李問小張。
小張笑了笑:「你需要的東西其實不多,但每一樣都很重要。就像開餐廳需要營業執照一樣,我們也需要一些基本的『證件』。」
小張在白板上寫下了準備清單:
1. AWS 帳號和權限
「首先,你需要一個 AWS 帳號,而且要有足夠的權限。」小張解釋,「就像你需要有權限才能在各個分店安裝監控設備一樣。」
需要的權限包括:
2. 現有的 EKS 集群
「當然,你需要一個正在運行的 EKS 集群。如果還沒有,我們需要先建立一個。」
3. kubectl 工具
「這是我們和 Kubernetes 溝通的工具,就像遙控器一樣。」
4. AWS CLI(可選)
「雖然我們主要用 Console 操作,但有時候命令列工具會很方便。」
小張打開 AWS Console,開始檢查環境:
「讓我們先看看你現在的 EKS 集群狀況。」她導航到 EKS 服務頁面。
「你看,這裡顯示你有一個叫 production-cluster 的集群,狀態是 Active,這很好。」小張指著螢幕說,「集群版本是 1.28,節點群組有 3 個節點,看起來一切正常。」
小李湊近螢幕:「這些數字代表什麼意思?」
「簡單來說,你的『城市』(集群)正在正常運作,有 3 棟『建築物』(節點)可以容納你的『居民』(Pod)。現在我們要給這座城市安裝一套完整的監控系統。」
「Container Insights 就像是我們城市的基礎監控系統,」小張解釋,「它會自動收集所有建築物(節點)和居民(容器)的基本資訊,比如他們用了多少電(CPU)、多少水(記憶體)、產生了多少垃圾(日誌)。」
小張開始實際操作:
打開 AWS Console
「首先,我們進入 AWS 管理控制台。」
導航到 CloudWatch
「在服務列表中找到 CloudWatch,或者直接在搜尋框輸入 'CloudWatch'。」
找到 Container Insights
「在左側選單中,找到『Insights』區塊,點擊『Container Insights』。」
小李看著螢幕:「哇,這個介面看起來很複雜。」
「別擔心,」小張安慰他,「我們一步一步來。你看到這個頁面顯示『No data available』,這是因為我們還沒有啟用監控。」
「現在系統會提示我們建立一些 IAM 角色,」小張說,「這就像給監控人員發放工作證,讓他們有權限進入各個區域收集資料。」
1. 建立 IRSA Role:
a. 請登入 AWS Management Console,並前往 https://console.aws.amazon.com/iam/ 開啟 IAM 主控台
b. 在主控台的導覽窗格中,請選擇「角色」,接著選擇「建立角色」
c. 請選擇 AWS 帳戶角色類型(Web identity)
- 在cloudshell 執行這段CLI 查詢 身分提供者
```
aws eks describe-cluster --name my-cluster --region us-east-1 --query "cluster.identity.oidc.issuer" --output text
```
- 選擇身分提供者(https://oidc.eks.us-east-1.amazonaws.com/id/3835xxxxxx)
- 選擇對象(sts.amazonaws.com)
d. 請選擇「下一步」
e. 請選取權限政策(CloudWatchAgentServerPolicy)
f. 請選擇「下一步」
g. 在「角色名稱」欄位中,請輸入您想要的角色名稱(需在您的 AWS 帳戶中保持唯一性)
h. 請檢視角色設定,確認無誤後選擇「建立角色」
「點擊『Set up Container Insights』後,系統會開始安裝必要的組件,」小張說,「這個過程大概需要 5-10 分鐘。」
小李看著進度條:「它在做什麼?」
「系統正在你的 EKS 集群中部署幾個重要組件:」
「安裝完成後,我們需要等待一些時間讓資料開始流入,」小張說,「就像新開的餐廳需要時間才會有客人一樣,監控系統也需要時間才會有資料。」
小李有點不耐煩:「要等多久?」
「通常 10-15 分鐘就會開始看到資料,」小張說,「我們可以先去喝杯咖啡。」
15 分鐘後,小張和小李回到電腦前:
檢查 Container Insights 儀表板
「現在重新整理 Container Insights 頁面,你應該會看到資料開始出現。」
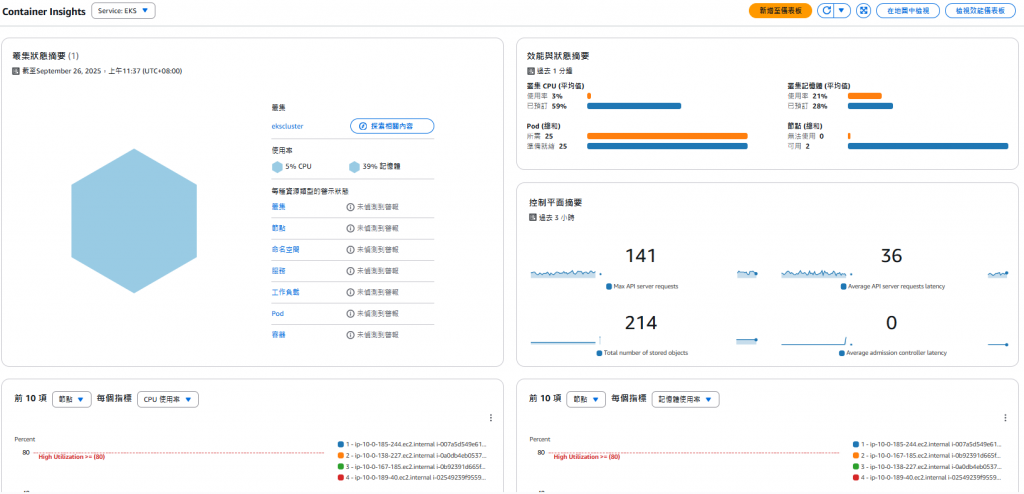
果然,原本空白的頁面現在顯示了各種圖表:
驗證資料收集
小張指著螢幕上的圖表:「你看,這裡顯示你的集群有 3 個節點,總共運行著 25 個 Pod,CPU 使用率平均 35%,記憶體使用率 42%。」
小李興奮地說:「這些數字是即時的嗎?」
「對,每分鐘更新一次。你可以看到這些線條在慢慢變化,就像心電圖一樣顯示你系統的『心跳』。」
小李看得目不轉睛:「這比我想像的還要詳細!」
「有了監控資料還不夠,」小張說,「我們需要設定告警,這樣當有問題時系統會主動通知我們,而不是等我們發現。」
「就像餐廳的火災警報器一樣?」小李問。
「沒錯!而且我們可以設定不同級別的告警,比如『注意』、『警告』、『緊急』。」
小張開始設定告警:
進入 CloudWatch Alarms
「在 CloudWatch 左側選單中,點擊『Alarms』。」
建立新告警
「點擊『Create alarm』按鈕。」
選擇指標
「我們先建立一個 CPU 使用率的告警。在指標瀏覽器中,選擇:」
ContainerInsights
node_cpu_utilization
production-cluster
設定條件
小張解釋告警條件:
「這意味著如果 CPU 使用率連續 10 分鐘超過 80%,就會觸發告警。」
配置通知
「現在我們需要設定當告警觸發時要通知誰。」
小張建立了一個 SNS 主題:
eks-alerts
「我們來測試一下告警是否正常工作,」小張說。
她暫時把 CPU 告警閾值調低到 30%:「這樣我們很快就會收到告警,確認系統正常運作。」
果然,幾分鐘後小李的手機響了,收到一封郵件:
ALARM: "EKS-CPU-High" in Asia Pacific (Tokyo)
Reason: Threshold Crossed: 1 out of the last 1 datapoints [35.2] was greater than the threshold (30.0).
「太神奇了!」小李驚呼,「它真的會主動通知我!」
小張把閾值調回 80%:「現在你知道告警系統是有效的。我們可以為不同的指標設定不同的告警。」
「預設的 Container Insights 儀表板很好,但每個企業都有自己的特殊需求,」小張說,「就像每家餐廳都有自己關注的重點指標一樣。」
小李點頭:「對,我最關心的是訂單處理速度和客戶滿意度,這些在預設儀表板上看不到。」
小張開始建立自訂儀表板:
進入 CloudWatch Dashboards
「在 CloudWatch 左側選單中,點擊『Dashboards』。」
建立新儀表板
「點擊『Create dashboard』,給它一個有意義的名稱,比如『Production EKS Overview』。」
添加第一個小工具
「我們先添加一個顯示集群整體健康狀況的小工具。」
小張選擇了「Line」圖表類型,然後配置:
node_cpu_utilization、node_memory_utilization
添加更多小工具
小張繼續添加:
「你可以調整每個圖表的大小、位置、顏色,」小張說,「讓儀表板符合你的使用習慣。」
她示範了幾個客製化選項:
小李看著完成的儀表板:「這看起來就像我們餐廳的中央監控室!」
「指標告訴我們『發生了什麼』,但日誌告訴我們『為什麼發生』,」小張解釋,「就像餐廳的監視器錄影,當有問題時我們可以回放查看詳細過程。」
小張導航到 CloudWatch Logs Insights:
選擇日誌群組
「Container Insights 會自動建立幾個日誌群組:」
/aws/containerinsights/production-cluster/application
/aws/containerinsights/production-cluster/host
/aws/containerinsights/production-cluster/dataplane
撰寫查詢
「我們可以用類似 SQL 的語法來查詢日誌。」
小張示範了幾個常用查詢:
查找錯誤日誌:
fields @timestamp, @message
| filter @message like /ERROR/
| sort @timestamp desc
| limit 100
分析回應時間:
fields @timestamp, @message
| filter @message like /response_time/
| stats avg(response_time) by bin(5m)
統計不同服務的日誌量:
fields @timestamp, kubernetes.pod_name
| stats count() by kubernetes.pod_name
| sort count desc
「讓我們來分析一個實際問題,」小張說。
她執行了一個查詢來查找最近的錯誤:
fields @timestamp, @message, kubernetes.pod_name
| filter @message like /500/ or @message like /ERROR/
| sort @timestamp desc
| limit 50
結果顯示了幾條錯誤記錄:
2024-03-15 14:30:25 ERROR: Database connection timeout payment-service-abc123
2024-03-15 14:30:20 HTTP 500: Internal server error order-service-def456
2024-03-15 14:30:15 ERROR: Redis connection failed cache-service-ghi789
「你看,這些錯誤都發生在同一時間段,而且都與連接有關,」小張分析,「這可能表示網路或基礎設施有問題。」
小李恍然大悟:「所以日誌不只是記錄,還能幫我們找到問題的模式!」
「監控系統很有用,但也會產生成本,」小張提醒,「我們需要在監控深度和成本之間找到平衡。」
她分享了幾個成本優化技巧:
1. 調整指標收集頻率
「不是所有指標都需要每分鐘收集一次。對於變化較慢的指標,可以調整為每 5 分鐘或 15 分鐘收集一次。」
2. 設定日誌保留期限
「根據合規要求和實際需求設定日誌保留期限:」
3. 使用日誌過濾
「只收集重要的日誌,過濾掉不必要的資訊。」
1. 合理設定告警閾值
「閾值設得太低會產生太多誤報,設得太高可能錯過真正的問題。建議根據歷史資料設定動態閾值。」
2. 使用標籤管理
「善用標籤來組織和過濾監控資料,這樣可以更快找到需要的資訊。」
3. 定期檢視和清理
「定期檢視監控配置,移除不再需要的告警和儀表板。」
安裝和配置完成後,小李看著滿螢幕的圖表和數據,感慨地說:「我從來沒想過監控一個系統需要這麼多細節。」
小張笑了:「這只是開始。監控系統就像一個活的生物,它會隨著你的業務成長而不斷演進。重要的是要持續學習和改進。」
「現在我們有了基礎的監控,接下來可以考慮:」
如果你也想為自己的 EKS 集群建立監控系統,記住這些要點:
「監控不是一次性的工作,而是一個持續的過程,」小張最後說,「但一旦建立起來,它會成為你最可靠的夥伴,幫助你更好地了解和管理你的系統。」
小李點點頭:「我已經迫不及待想看到明天的監控報告了!」
這個故事展示了如何使用 AWS Console 為 EKS 集群安裝和配置 CloudWatch 可觀測性套件。雖然過程看似複雜,但每一步都有其重要意義。記住,好的監控系統不是一天建成的,需要時間、耐心和持續的改進。


 iThome鐵人賽
iThome鐵人賽